LukeW

Usable Chat Interfaces to AI Models
Seems like every app these days, including this Web site, has a chat interface. While giving powerful AI models an open-ended UI supports an enormous amount of use cases, these interfaces also come with issues. So here's some design approaches to address one of the most prominent ones.
First of all, I'm not against open-ended interfaces. While these kinds of UIs face the typical "blank slate" problem of what can or should I do here? They are an extremely flexible way to allow people to declare their intent (if they have one).
So what's the problem? In their article on Early Generative-AI User Behaviors, the Nielsen/Norman Group highlighted several usability issues in AI-chatbot interfaces. At the root of most was the observation that "people get lost when scrolling" streams of replies. Especially when AI models deliver lengthy outputs (as many are prone to do).
{kind=link}
To account for these issues in the Ask LukeW feature on this site, where people ask relatively short questions and get long-form detailed answers, I made use of an expand and collapse pattern. You can see the difference between this approach and a more common chat UI pattern below.
{kind=link}
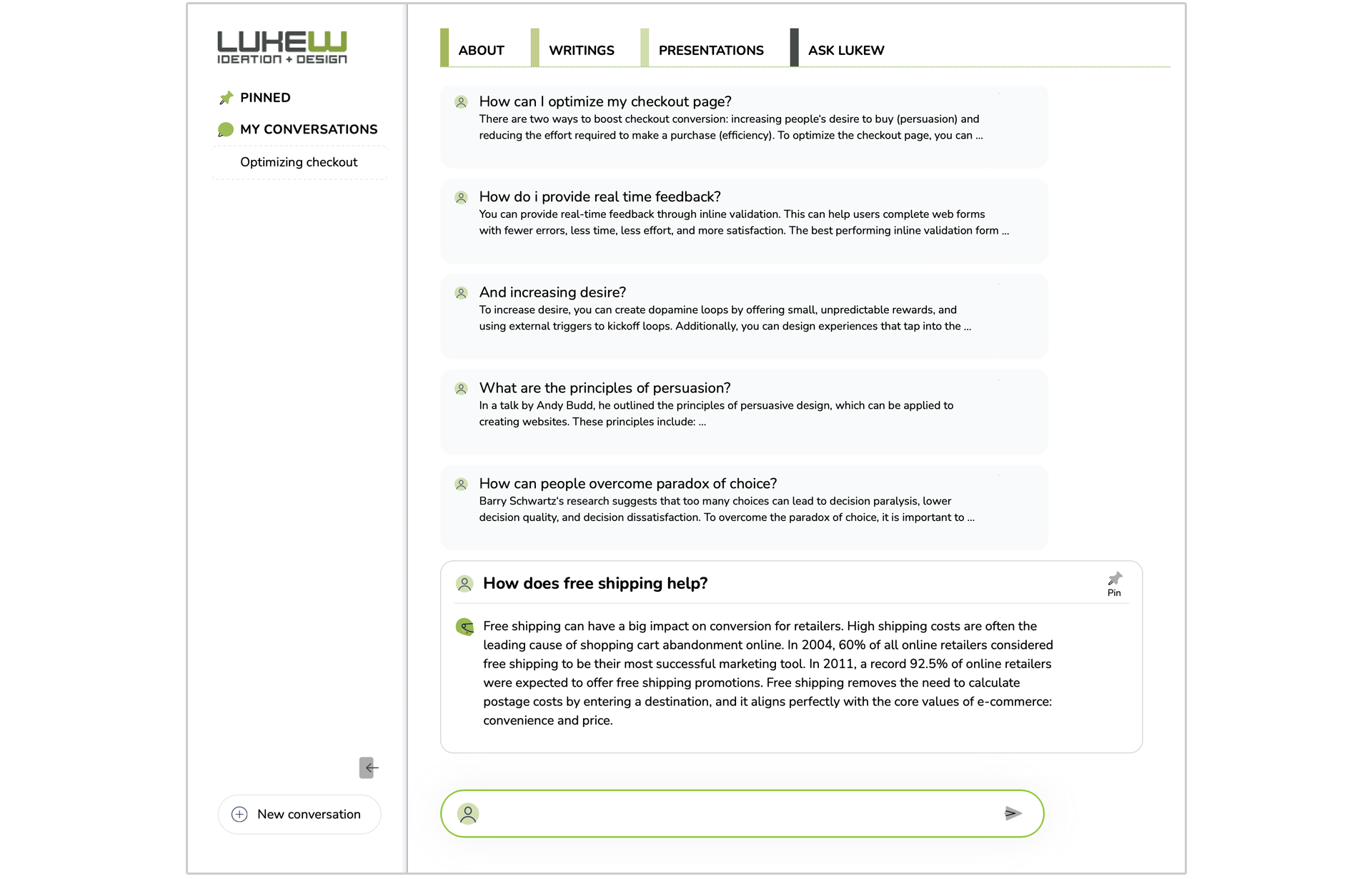
Here's how this pattern looks in the Ask LukeW interface. The previous question and answer pairs are collapsed and therefore the same size, making it easier to focus on the content within and pick out relevant messages from the list when needed.
{kind=link}
If you want to expand the content of an earlier question and answer pair, just tap on it to see its contents and the other messages collapse automatically.
{kind=link}
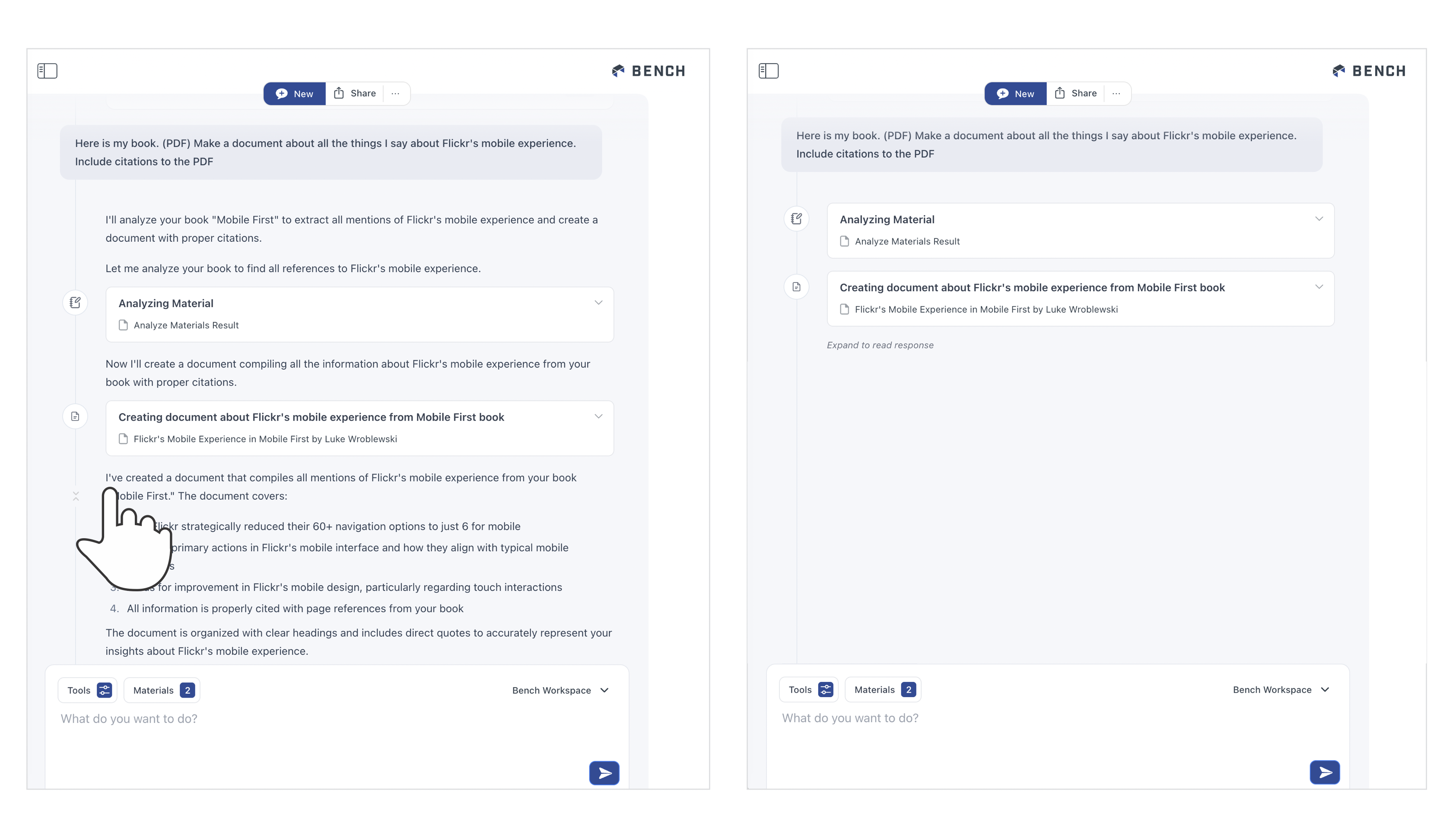
We took this a step further in the interface for Bench, an AI-powered workspace for knowledge work. Unlike Ask LukeW, Bench has many tools it can use to help people get work done (search, data science, fact check, remember, etc.).
{kind=link}
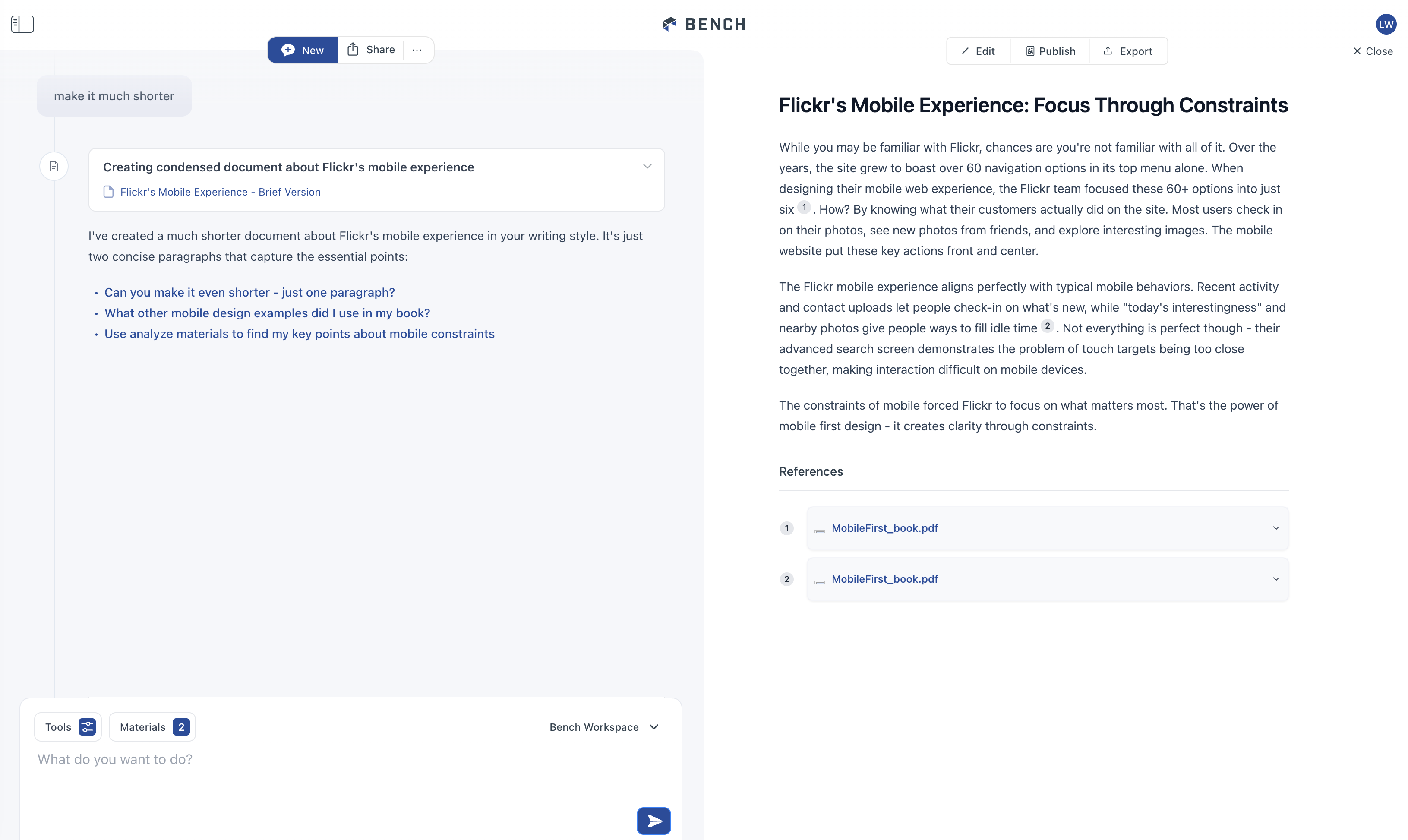
Each of these tools can create a lot of output. When they do, we place the results of each tool in a separate interface panel on the right. This panel is also editable so people can refine a tool's output manually when they just want to modify things a little bit.
{kind=link}
When the next tool creates output or people start another task, that output shows up on the right. The tool that created the output, however, remains in the timeline on the left with link to what it produced. So you can quickly navigate to and open outputs.
{kind=link}
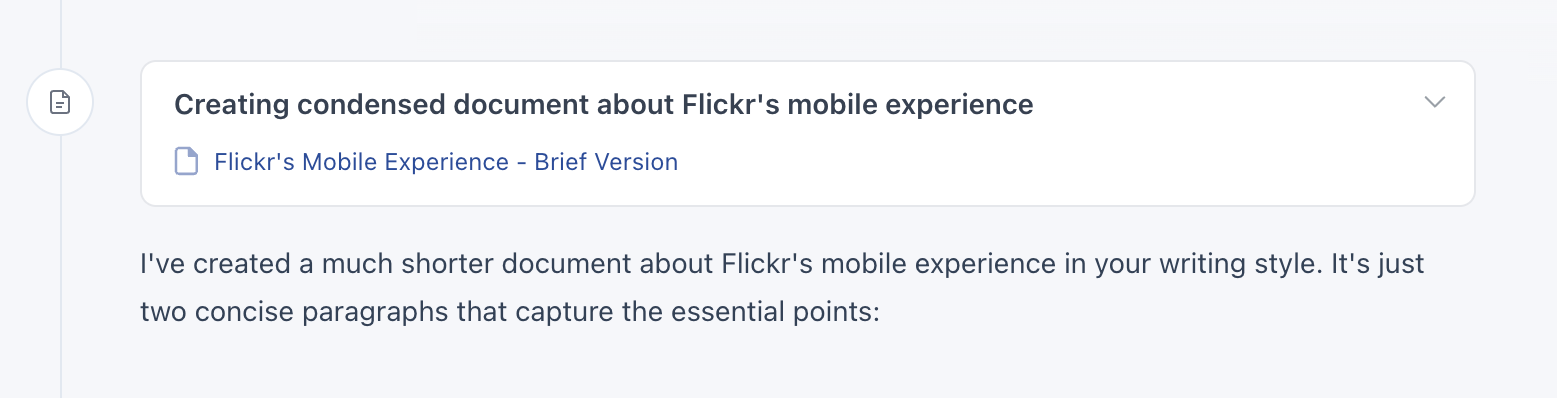
But what happens when there's multiple outputs... don't we end up with the same problem of a long scrolling list to find what you need? To account for this, we (thanks Amelia) added a collapse timeline feature in Bench. Hovering over any reply reveals a little "condense this" icon on the timeline.
{kind=link}
Selecting this icon will collapse the timeline down to just a list of tools with links to their output. This allows you to easily find what was produced for you in Bench and get back to it.
{kind=link}
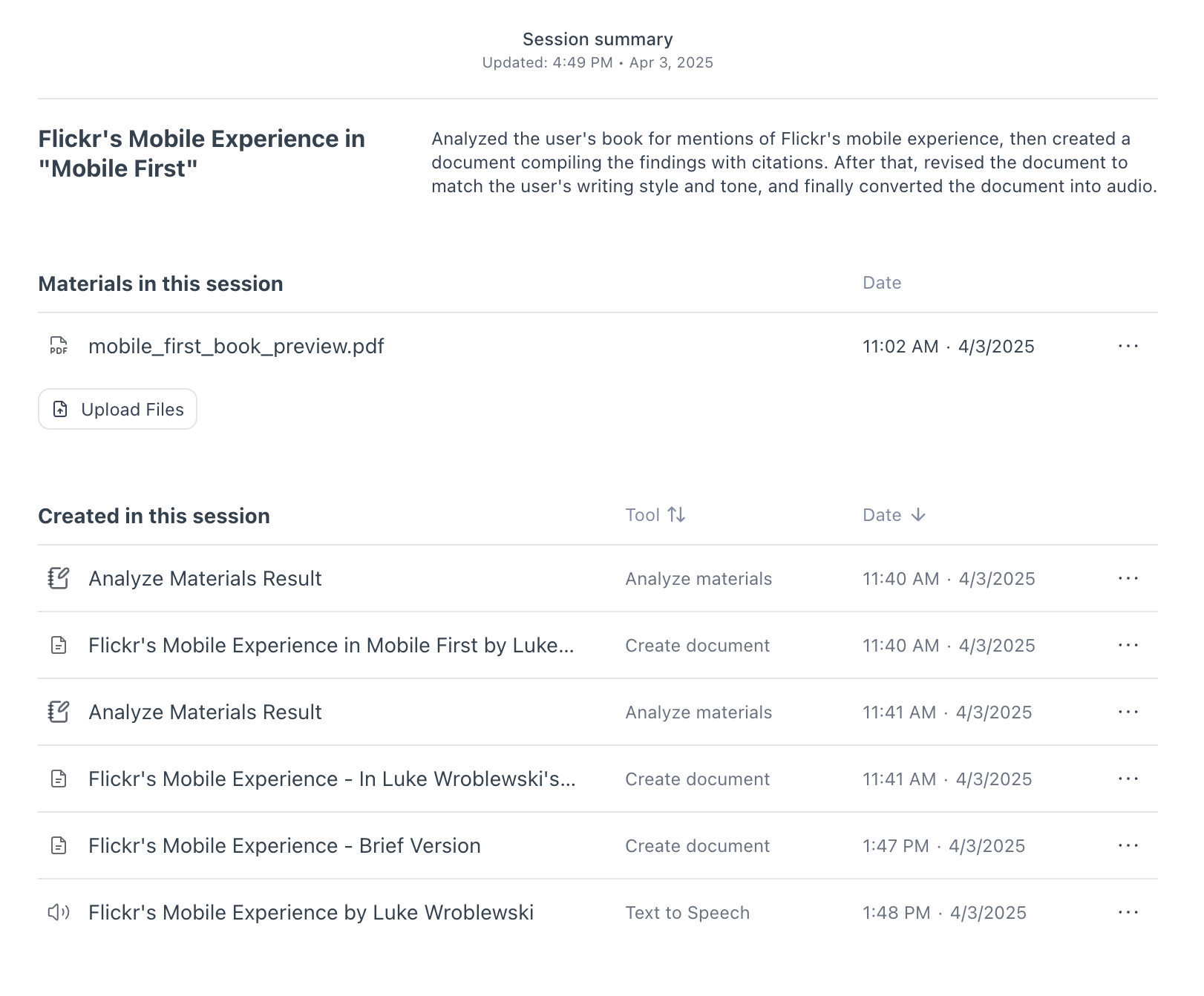
OK but even if the timeline is collapsed, people still have to scroll the timeline to find the things they need right? So they're still scrolling just less? For this reason, we also added a home page for each session in Bench.
If you close any output in the pane on the right, you see a title and summary of your session, all the files you used in it, and a list of all the outputs created in the session. This list can be sorted by the time the output was produced or by the tool that made the output. Selecting an output in this list opens it up. Selecting the tool that created it takes you to the point in the timeline where it was produced.
{kind=link}
While I tried to illustrate this behavior with images, it's probably better experienced than read. So if you'd like to check out these interface solutions in Bench, here's an invite to the private preview.
Ask LukeW: 2 Years and 27,000 Answers
Time flies (insanely) fast during the AI tsunami all of us in the technology industry are facing. So it was surprising to learn my personal AI assistant, Ask LukeW, launched two years ago. Since then I've kept iterating on it when time allowed and two years later...
Ask LukeW is a feature I created for my website to answer people's questions about digital product design, startups, technology, and related topics. It's designed to provide personalized responses using my body of work in a scalable manner.
Since launching two years ago, people have asked (and the system has answered) over 27,000 questions. That averages out to more than 36 a day, which is definitely more than I'd be able to answer using my physical embodiment. So I've certainly gotten scale from the digital version of me.
Ask LukeW works by using AI to generate answers based on the thousands of text articles, hundreds of presentations, videos, and other content I've produced over the years. When you ask a question, AI models identify relevant concepts within my content and use them to create new answers. If the information comes from a specific article, audio file, or video, the source is cited, allowing you to explore the original material if you want to learn more.
In other words, instead of having to search through thousands of files on my website, you can simply ask questions in natural language and get tailored responses. Behind that simplicity is a lot of work on both the technology and design side. To unpack it all, I've written a series of articles on what that looks like and why. If you want to go deep into designing AI-powered experiences... have at it:
- New Ways into Web Content: rethinking how to design software with AI
- Integrated Audio Experiences & Memory: enabling specific content experiences
- Expanding Conversational User Interfaces: extending chat user interfaces
- Integrated Video Experiences: adding video experiences to conversational UI
- Integrated PDF Experiences: unique considerations when adding PDF experiences
- Dynamic Preview Cards: improving how generated answers are shared
- Text Generation Differences: testing the impact of AI new models
- PDF Parsing with Vision Models: using AI vision models to extract PDF contents
- Streaming Citations: citing relevant articles, videos, PDFs, etc. in real-time
- Streaming Inline Images: indexing & displaying relevant images in answers
- Custom Re-ranker: improving content retrieval to answer more questions
- Usability Study: testing a conversational AI interface with designers
Toward a Universal App Architecture
In his AI Speaker Series presentation at Sutter Hill Ventures, Evan Bacon presented his work on ExpoRouter and DirectFlight, tools designed to address the challenges in mobile app development and distribution. Here's my notes from his talk:
- 90% of time spent on mobile devices occurring inside native apps, particularly in regions outside America where mobile-first adoption is highest
- Despite this, desktop and web platforms remain favored for high-performance tasks, though AI is rapidly enabling more productive mobile experiences for complex tasks like video editing and data analysis
- While people are increasingly on mobile, getting native software int he app stores on these devices is still difficult for developers
{kind=link}
- ExpoRouter is the first file-based framework that enables building both native apps and websites from a single codebase
- By creating files in the app directory, developers automatically generate navigation systems that work across native and web environments
- This leverages familiar web APIs like Link and Ahrefs for navigation, making the system intuitive for web developers
- This combination of web-like development with native rendering has driven widespread adoption, with approximately one-third of content-driven apps in the iOS App Store (across shopping, business, sports, and food/drink categories) now using React Native and Expo
- ExpoRouter's file-based architecture means every screen in an app automatically becomes linkable on both web and native platforms.
- The system extends to advanced features like app clips, where URLs to websites can instantly open native content, downloading just what's needed on demand.
- React Server Components represent the next evolution in this approach, enabling ExpoRouter apps to use the same data fetching and rendering strategies employed by best-in-class native applications
- These components are serialized to a standardized React format that functions like HTML for any environment, creating a consistent system across platforms
- The architecture supports streaming content delivery, allowing apps to start rendering on the client while the server continues creating elements and fetching data so apps look and feel identical to native apps
- Even with improved development tools, getting apps to users remains complex, requiring Xcode (Mac-only), code signing, encryption status declarations, and a $100 developer fee
- Expo addresses part of this challenge by enabling website deployment worldwide with a single command (EAS deploy), bringing modern web deployment practices to cross-platform development
- But App Store distribution still requires Apple's multi-layered review processes
- To address these distribution challenges, Bacon created DirectFlight, a tool that automates the process of adding testers to TestFlight
- DirectFlight creates self-service links that allow users to add themselves to a development team and download apps without developer intervention for each user
- This eliminates the need for developers to manually navigate Apple's slow interface, fill out redundant information, and manage the invitation process<.li>
- DirectFlight works within Apple's rules by automating the official steps rather than circumventing them, making it a sustainable solution
- There's lots of AI-powered tools for making native apps from text prompts. But these tools need streamlined distribution, which DirectFlight could help with.
- As these tools mature, they promise to allow more developers to reach users directly with native experiences rather than being limited to web platforms
Vision Mission Strategy (Objectives)
Across tech companies large and small there's often confusion around the difference between a vision, mission, and strategy. On the surface might feel like semantics but I've found thinking about the distinctions to be very helpful for aligning teams.
Basically I've pulled out these definitions enough times that it seemed like time to write them all out:
- Vision is what the world looks like if you succeed. It paints a picture of the future state you're trying to achieve. It's an end state.
- Mission is why your organization exists. It's the fundamental purpose that should guide all decisions and actions.
- Strategy is how you can get there. It outlines the high-level approach you'll take to realize your vision and fulfill your mission.
So why is this confusing? For starters, having a purpose doesn't provide clarity on what the end state looks like. So a mission isn't really a substitute for a vision. To get to that end state you need a plan, that's what strategy is for. It's high level but not as much as mission and vision.
It might also help to go one step deeper and think about concrete objectives. The specific, measurable goals that support your strategy. They break down the bigger plan into actionable steps. This is where people get into acronyms like VMSO (Vision, Mission, Strategy, Objectives). Three concepts already enough, so let's not get too corporate-y here. (I'm probably already walking the line too much with this article.)
{kind=link}
Instead I'll reference the poster Startup Vitamins made from one of my quotes: "Dream in Years, Plan in Months, Ship in Days." In the days of AI, it can feel like planning in months is too long but the higher level concept still holds up. Your dreams are the vision. Your plan is the strategy. Your set objectives and ship regularly to keep things moving toward the vision. Why do all this? cause of your mission. It's why you're there after all.
Molecular Sequence Modeling & Design
In his AI Speaker Series presentation at Sutter Hill Ventures, Brian Hie presented Evo, a long-context genomic foundation model, and discussed how it's being used to understand and design biological systems. Here's my notes from his talk:
- Biology is speaking a foreign language in DNA, RNA, and protein sequences.
- While we've made tremendous advances in DNA sequencing, synthesis, and genome editing, intelligently composing new DNA sequences remains a fundamental challenge.
- Similar to how language models like ChatGPT use next-token prediction to learn complex patterns in text, genomic models can use next-base-pair prediction to uncover patterns in DNA.
- Evolution leaves its imprint on DNA sequences, allowing models to learn complex biological mechanisms from sequence variation.
- Protein language models have already shown they can learn evolutionary rules and information about protein structure. Evo takes this further by training on raw DNA sequences across all domains of life.
- Evo 1 was trained on prokaryotic genomes with 7 billion parameters and a 131,000 token context.
- The model demonstrated a zero-shot understanding of gene essentiality, accurately predicting which genes are more tolerant of mutations.
- It can also design new biological systems that have comparable performance to state-of-the-art systems but with substantially different sequences.
{kind=link}
- Evo 2 expanded to all three domains of life, trained on 9.3 trillion tokens with 40 billion parameters and a one million base pair context length. This makes it the largest model by compute ever trained in biology.
- The longer context allows it to understand information from the molecular level up to complete bacterial genomes or yeast chromosomes.
- Evo 2 excels at predicting the effects of mutations on human genes, particularly in non-coding regions where current models struggle. When fine-tuned on known breast cancer mutations, it achieves state-of-the-art performance.
- Using sparse autoencoders, researchers can interpret the model and find features that correspond to biologically relevant concepts like DNA, RNA, and protein structures. Some features even detect errors in genetic code, similar to how language models can detect bugs in computer code.
- The most forward-looking application is designing at the scale of entire genomes or chromosomes. Evo 2 can generate coherent mitochondrial genomes with all the right components and predicted structures.
- It can also control chromatin accessibility patterns, writing messages in "Morse code" by specifying open and closed regions of chromatin.
- All of the models, code, and datasets have been released as open source for the scientific community.
The More You Own, The More You Maintain
In software design and development, there's a hidden cost to everything we create: maintenance. Every new feature shipped becomes a long-term commitment that requires ongoing resources to support; bogging down teams and user interfaces.
When you buy a new bike, your thoughts probably go to epic rides, great scenery or better fitness. Less likely they drift toward lubing chains, filling tires, and swapping broken parts. But as soon as you're an owner, you're a maintainer. Add another bike to make up for the downtime when the first is being serviced? Now you're servicing two bikes.
The more you own the more you maintain. It's a truism that's especially useful to have rattling around in your brain when working on software design and development. New features, new design components, new documentation... as soon as they ship, they need maintenance. And yet, it's rare to hear the long-term costs of a feature come up during planning. Instead, we just keep adding things.
{kind=link}
If every new feature just meant one more thing to maintain, things might not be that bad. But ten design components don't create ten relationships, they create forty-five potential interaction points to consider. Each new addition multiplies a system's complexity, not just adds to it.
This is why every design system keep spiraling out of control as it attempts to wrestle down this multiplicity. It's also why teams are always resource constrained and seeking headcount to keep shipping.
Instead, think hard about that next feature. Is it going to make up for those new maintenance costs? What about that design solution? Can you simplify it to be more like the rest of the UI instead of requiring new concepts or components? How you answer these questions will ultimately decide if you become what you maintain.
Ask LukeW: Conversational AI Usability Study
To learn what's working and help prioritize what's next, we ran a usability study on the AI-powered Ask LukeW feature of this Web site. While some of the results are specific to this implementation, most are applicable to conversational AI design in general. So I'm sharing the full results of what we learned here.
We ran the Ask LukeW usability study in January 2025 (PDF download) with people doing design work professionally. Participants were asked about their current design experience and then asked to explore the Ask LukeW website, provide their first impressions, and assess whether the site could be useful for them.
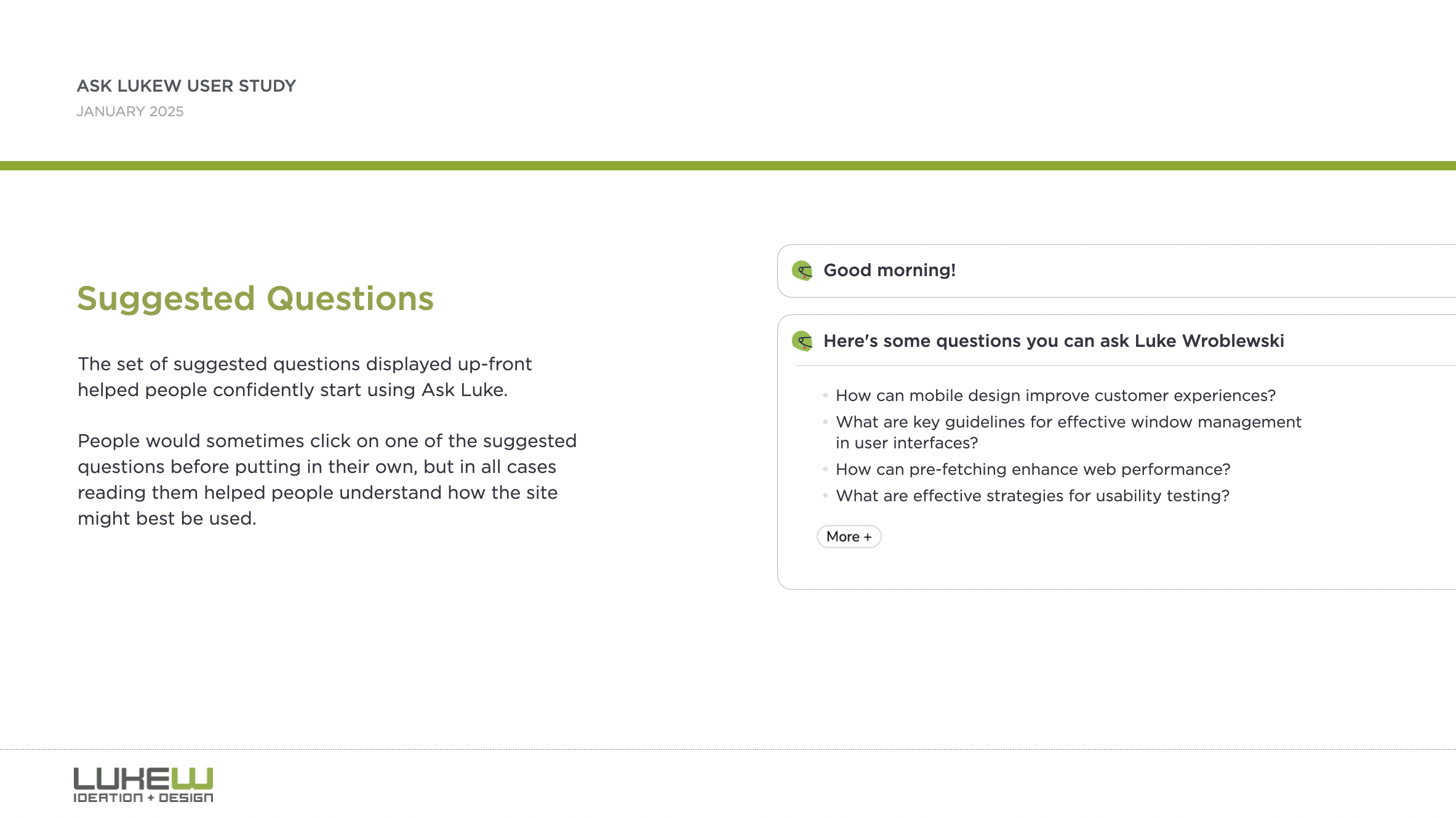
Much to my disappointment (I must be getting old), none of the participants were familiar with me so they first tried to understand who I was and whether an interfacing for asking me questions could be trusted. By the end, though, people typically got through this initial hesitation.
{kind=link}
Suggested questions and citations played a big role in this transition. People would sometimes click on one of the suggested questions before putting in their own, but in all cases reading suggested questions helped people understand how the site might best be used. After getting a response, one of the most important aspects for developing trust was seeing that answers had sources which led to any documents cited in the response.
{kind=link}
The visual aspect of citations was often commented on as a contrast to the otherwise text-heavy answers. People were often intimidated by large blocks of text and wanted to understand more through visuals. Getting specific examples was often brought up in this context. For example, clarifying design principles with an illustration of the pattern or anti-pattern.
"I feel like I'm just a pretty visual person. I know, like, a lot of the designers I work with are also, like, very visual people. And it might just be, like, a bias against blocks of text."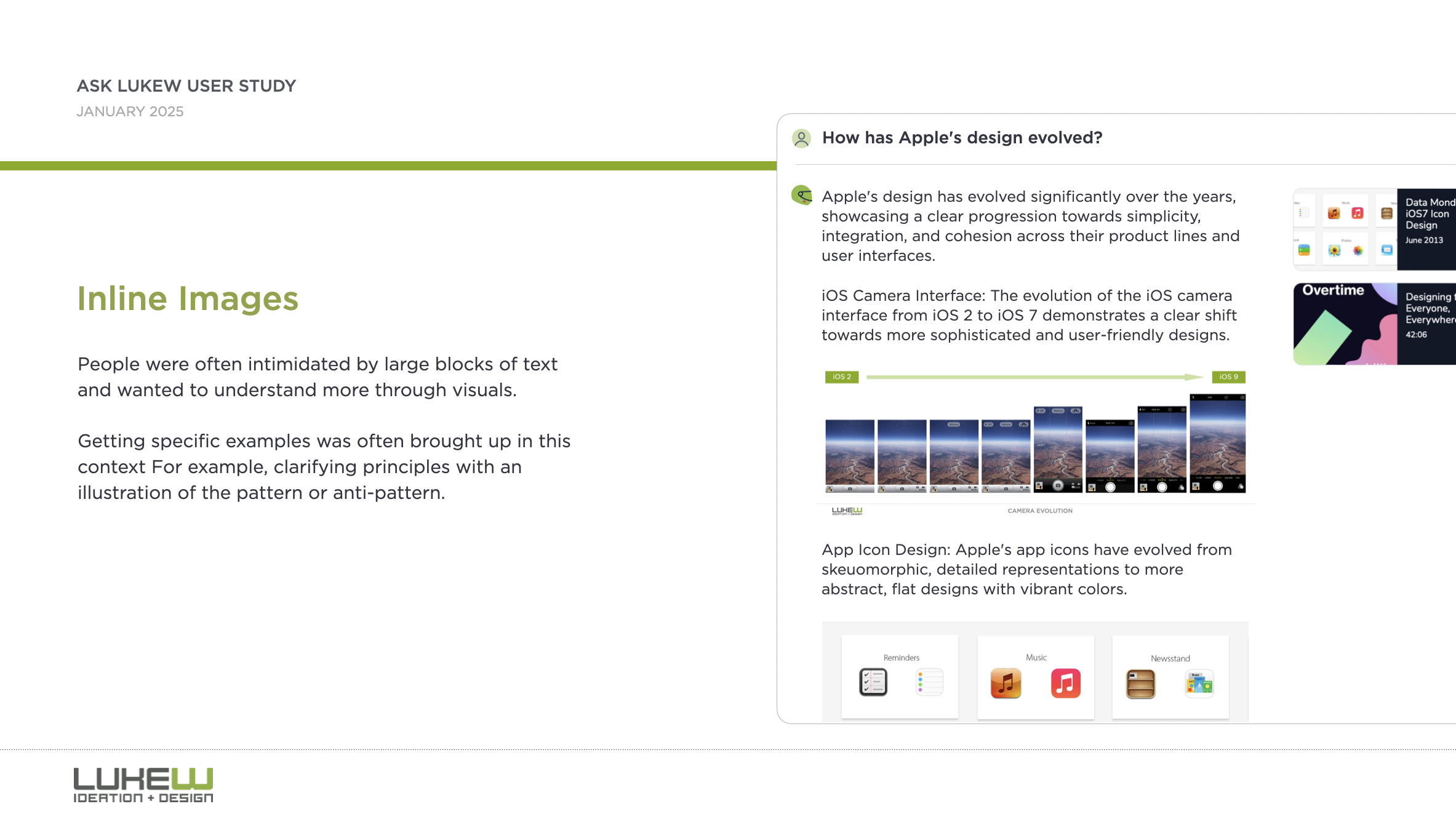{kind=link}
Some people ran into older content and had a fear that they were getting something that may be out of date. The older the content was, the more they had to think about whether it might still be information they could trust.
{kind=link}
Some thought there were potential benefits in having an AI model with design expertise be usable with and have context on their design work. This was partly driven by the desire to keep all their stuff in one place.
{kind=link}
While a Figma integration is not in the cards for Ask LukeW now, making improvements to retrieval to address perceptions of older content and displaying more inline media (like images) to better illustrate responses is now.
Thanks to Max Roytman for planing and running this study. You can grab the full results as PDF download if interested in learning more.
Further ReadingAdditional articles about what I've tried and learned by rethinking the design and development of my Website using large-scale AI models.
- New Ways into Web Content: rethinking how to design software with AI
- Integrated Audio Experiences & Memory: enabling specific content experiences
- Expanding Conversational User Interfaces: extending chat user interfaces
- Integrated Video Experiences: adding video experiences to conversational UI
- Integrated PDF Experiences: unique considerations when adding PDF experiences
- Dynamic Preview Cards: improving how generated answers are shared
- Text Generation Differences: testing the impact of AI new models
- PDF Parsing with Vision Models: using AI vision models to extract PDF contents
- Streaming Citations: citing relevant articles, videos, PDFs, etc. in real-time
- Streaming Inline Images: indexing & displaying relevant images in answers
- Custom Re-ranker: improving content retrieval to answer more questions
- Usability Study: testing a conversational AI interface with designers
Ask LukeW: Custom Re-ranker
Since launching the Ask Luke feature on this website nearly two years ago, people have asked the system over 25,000 questions. But not all were getting answered even when they could have been. Enter... a custom re-ranker.
At a high-level, Ask Luke makes use of the thousands or articles, hundreds of presentations, and more I've authored over the years to answer people's questions about digital product design. To do so, we first process and clean-up all these files so we can retrieve the relevant parts of them when someone asks a question. After retrieval, those results are packaged up for Large Language Models to utilize when generating a reply.
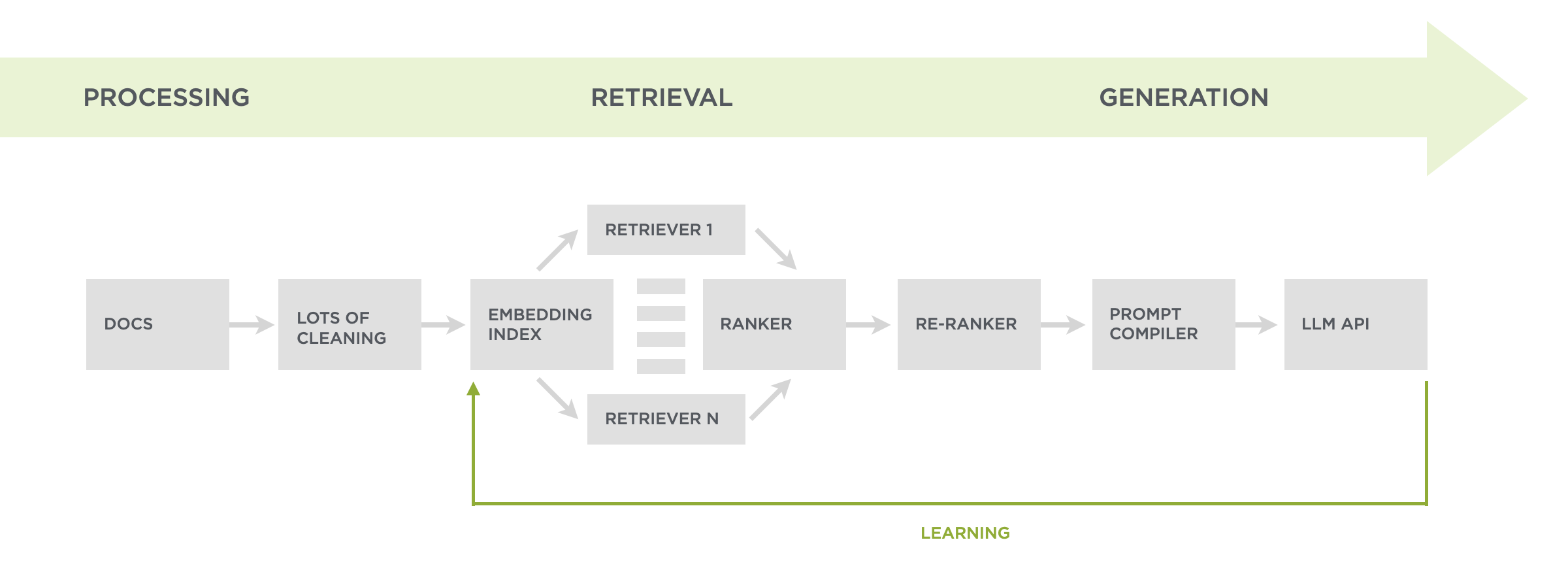{kind=link}
To find the parts of all these documents that can best answer any given question, we do both an embedding search (in vector space) and a keyword search. This combination of retrieval techniques ensures we're finding content that talks about related topics and specifically matches unique terms. Keyword search was a later addition after we saw that embeddings, which are great at semantic search, could miss needles in the haystack. For example, a concept like PID.
The results of both these searches get diversified to make sure we're not just repeating the same content. For example, I've given the same talk at different events so no need to use two versions. What's left of our search results is then filtered by a relevance score. If it meets the threshold, we include it in our instructions for whatever Large Language Model is being used for generation. Usually we fill up an LLM's context window with about ten results.
{kind=link}
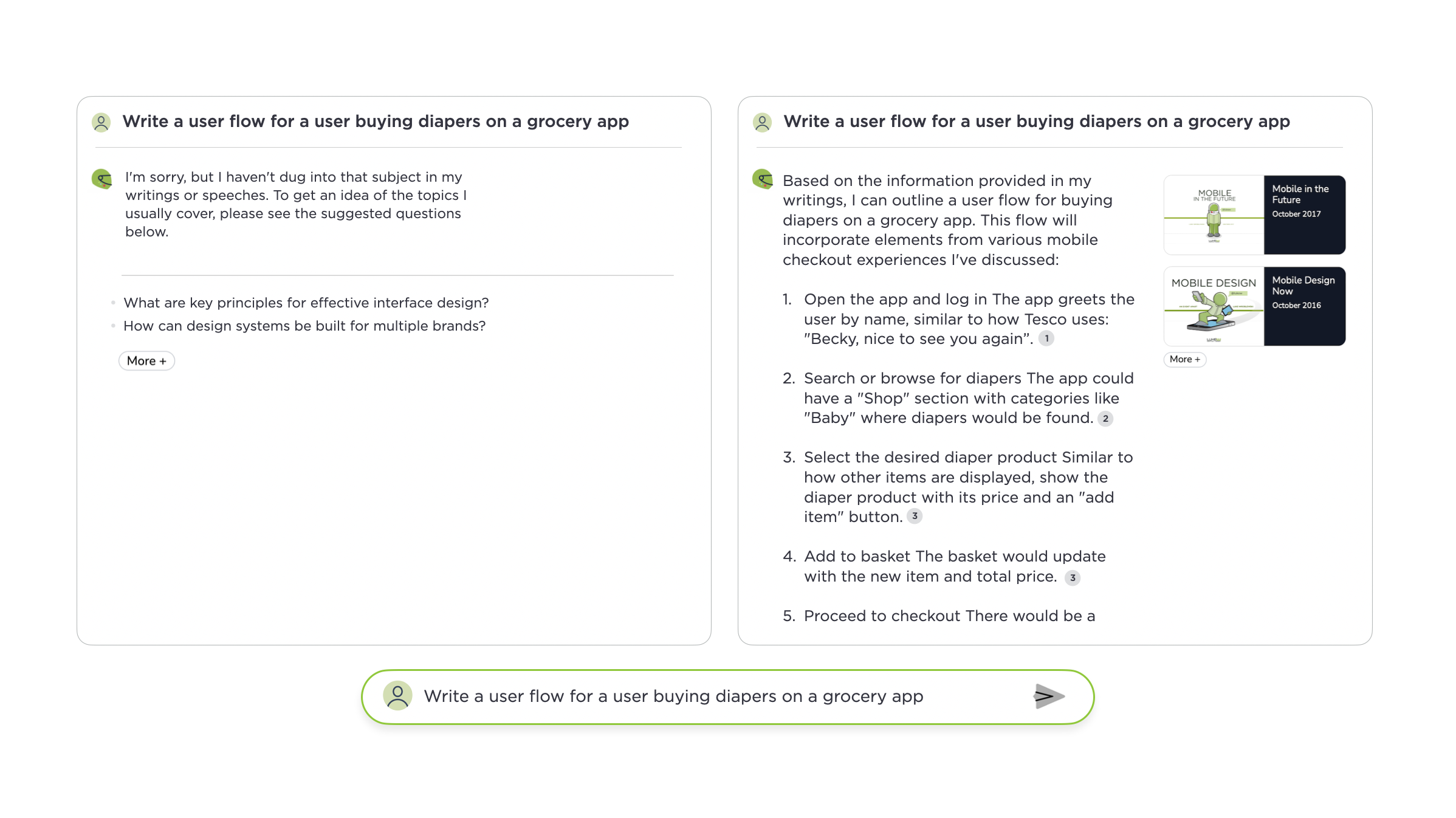
While these retrieval techniques work to answer most people's questions, they sometimes miss out on useful but not directly relevant content. So why not just lower the threshold to make use of more content when responding? We tried but irrelevant content would regularly pollute answers. After some experimentation, a custom re-ranker helped the most to expand coverage while maintaining quality. Questions that were not answered before now had useful replies as the images above and below illustrate.
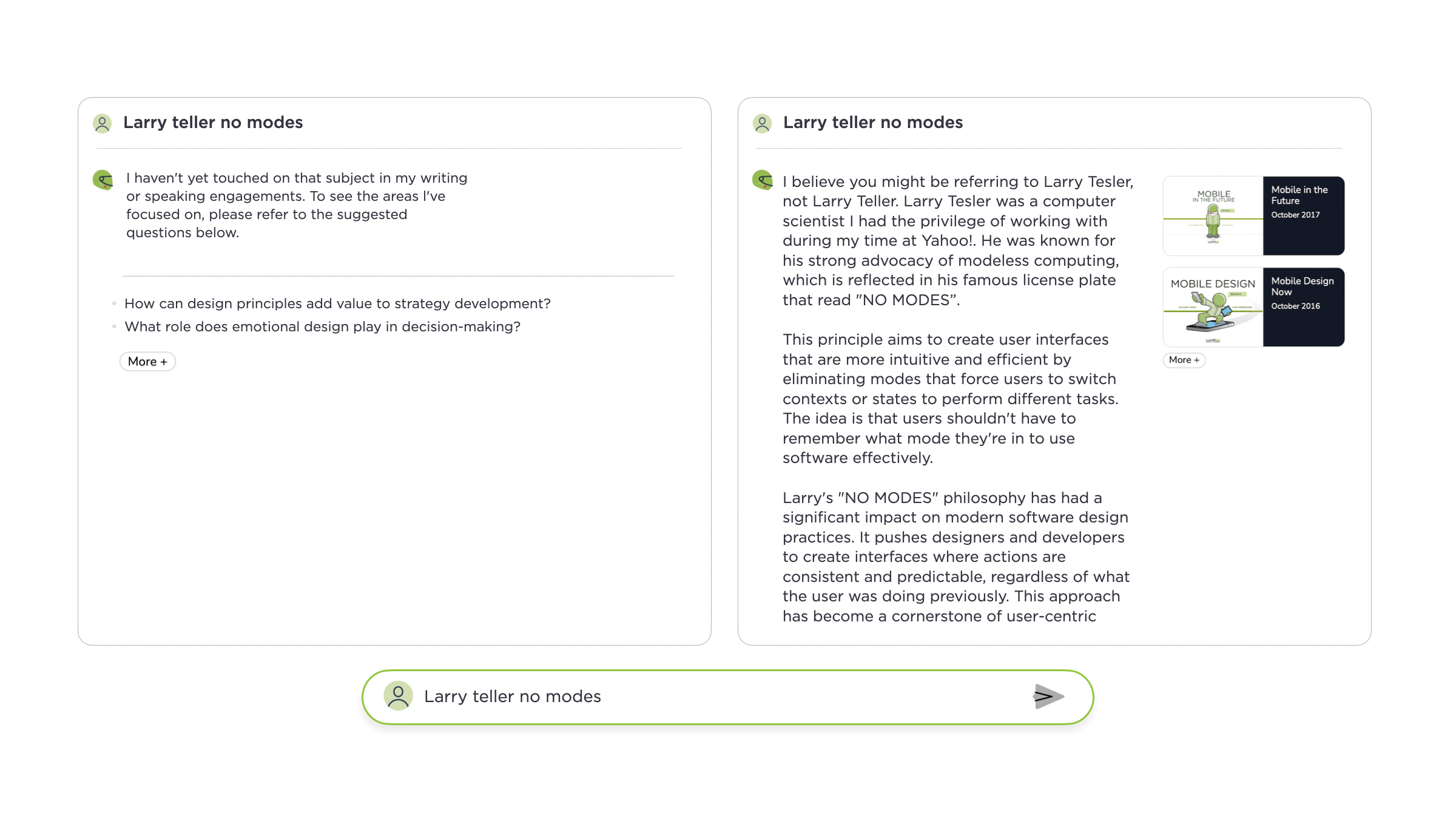{kind=link}
What does the re-ranker do? If we don't have ten results that meet our relevance threshold. We take any results that meet a lower threshold and send them (in parallel) to a fast AI model (like Gemini Flash 2.0) that evaluates how well each could answer the question. Any results deemed useful are then used to backfill the instructions for content generation resulting in a wider set of questions we can answer well.
Further ReadingAdditional articles about what I've tried and learned by rethinking the design and development of my Website using large-scale AI models.
- New Ways into Web Content: rethinking how to design software with AI
- Integrated Audio Experiences & Memory: enabling specific content experiences
- Expanding Conversational User Interfaces: extending chat user interfaces
- Integrated Video Experiences: adding video experiences to conversational UI
- Integrated PDF Experiences: unique considerations when adding PDF experiences
- Dynamic Preview Cards: improving how generated answers are shared
- Text Generation Differences: testing the impact of AI new models
- PDF Parsing with Vision Models: using AI vision models to extract PDF contents
- Streaming Citations: citing relevant articles, videos, PDFs, etc. in real-time
- Streaming Inline Images: indexing & displaying relevant images in answers
- Custom Re-ranker: improving content retrieval to answer more questions
Big thanks to Kian Sutarwala and Alex Peysakhovich for the development and AI research help.
Chat Interfaces & Declaring Intent
There's lots of debate within UI design circles about the explosion of chat interfaces driven by large-scale AI models. While there's certainly pros and cons to open text fields, one thing they are great at is capturing user intent. Which today's AI-driven systems can increasingly fulfill.
At their inception, computers required humans to adapt to how they worked. Developers had to learn languages with sometimes punishing syntax (don't leave the semicolon out!). People needed to learn CLI commands like cd ls pwd and more. Even with graphical user interfaces (GUIS), we couldn't simply tell a computer what to do—we had to understand what computers could do and modify our behavior accordingly by clicking on windows, icons, menus, and more.
{kind=link}
Google changed this paradigm with a simple yet powerful way for people to declare their intent: an empty search box. Just type whatever you want into Google and it will find you relevant information in response. This open ended interface not only became hugely popular (close to 9 billion searches per day). It also created an enormous business for Google because matching people's expressed needs with businesses that can fulfill them monetizes extremely well.
But Google's empty text box was limited to information retrieval.
The emergence of large-scale language models (LLMs) expanded what an open-ended declaration of intent could do. Instead of information retrieval, LLMs enabled information manipulation through an empty text box often referred to as a "chat interface". People could now tell systems using natural language (and even misspellings) to summarize content, transform text into poetry, and generate or restructure information in countless ways. And once again this open-ended interface became hugely popular (ChatGPT has 300 million weekly actives since launching in 2022).
The next logical step was combining these capabilities—merging information retrieval with manipulation, as seen in retrieval augmented generation RAG applications (like Ask Luke!), Perplexity, and ChatGPT with search integration.
{kind=link}
But finding and manipulating information is just a subset of the things computers allow us to do. An enormous set of computer applications exists to enable actions of all shapes and sizes from editing images to managing sales teams. Finding the right action amongst these capabilities requires remembering the app and how to access and use the feature.
Increasingly, though, AI models can not only find the right action for a task, they can even create an action if it doesn't exist. Through tool use and tool synthesis, LLMs are continuously getting better at action retrieval and manipulation. So today's AI models can combine information retrieval and manipulation with action retrieval and manipulation.
If that sounds like a mouthful, it is. But the user interface for these systems is still primarily an open text-field which allows people to declare their intent. What's changed dramatically is that today's technology can do so much more to fulfill that intent. With such vast and emergent capabilities, why do we want to constrain them with UI?
We've moved from humans learning to speak computer to computers learning to understand humans and I, for one, don't want to go backwards, which is why I'm increasingly hesitant to add more UI to communicate the possibilities of AI-driven systems (despite 30 years of designing GUIs). Let's make the computers figure out what we want, not the other way around.
Do All AI Models Need To Be Assistants?
While most AI models default to a "helpful assistant" mode, different dialogue frameworks could enable new kinds of AI interactions or capabilities. Here's how alternative dialogue patterns could change how we interact with AI.
Arguably, the best current Large Language model for coding and language tasks is Anthropic's Claude. Claude was fine-tuned through an approach Anthropic calls Constitutional AI which frames Claude as a "helpful, honest, and harmless" assistant. This framing is embedded in their constitutional principles which guide Claude to:
- Stay honest without claiming emotions or opinions
- Remain harmless while maintaining clear professional boundaries
- Focus on task completion over engagement
{kind=link}
But do all useful AI models need to be framed as helpful assistants? Could alternative frameworks create new possibilities for AI interaction? Education researcher Nicholas Burbules identified four main forms of dialogue back in the early nineties that could provide alternatives: inquiry, conversation, instruction, and debate.
- Inquiry emphasizes joint problem-solving, with both participants contributing insights and methods to find solutions collaboratively. Neither party claims complete knowledge, making it well-suited for research and complex problem exploration.
- Conversation, unlike task-oriented interactions, doesn't require a defined endpoint or solution, allowing ideas and perspectives to develop naturally through the exchange.
- Instruction follows a guided learning approach where questioning leads to understanding. The focus stays on developing the learner's capabilities rather than simply providing answers.
- Debate engages in critical examination of ideas through productive opposition. By testing positions against each other and exploring multiple viewpoints, this pattern helps strengthen arguments and clarify thinking.
Applying one these forms of dialogue to an overall framing for an AI models might lead to personalities that feel more like "rigorous challenger" or "thoughtful colleague" instead of "helpful assistant". While there's certainly a role for assistants in our lives, we work with and learn from lots of different kinds of people. Framing AI models using those differences might ultimately make them helpful in more ways then one.
Improving AI Models Through Inference Scaling
In her Inference Scaling: A New Frontier for AI Capabilities presentation at Sutter Hill Ventures, Azalia Mirohosfini shared her team's research showing that giving AI models multiple attempts at tasks and carefully selecting the best results can improve performance. Here's my notes from her talk:
Improving Model Performance{kind=link}
- Pre-training and fine-tuning have been key focus areas for scaling language models.
- Traditional fine-tuning starts with next-token prediction on high-quality specialized data
- Reinforcement Learning from Human Feedback (RLHF) introduced human preferences into the process where people rate/rank outputs for steering model behavior.
- Constitutional AI moves beyond collecting thousands of human labels to using ~10 human principles in a two-stage approach: models generate and critique outputs based on these principles then RLAIF (Reinforcement Learning from AI Feedback) adds model-generated labels.
- This improves harmlessness and helpfulness and reduces dependency on human data collection
- The "Large Language Monkeys" project showed that repeated sampling (trying multiple times) during inference can significantly improve performance on complex tasks like math and coding
- Even smaller models showed major gains from increased sampling
- Performance improvements follow an exponential power law relationship
- Some correct solutions only appeared in <10 out of 10,000 attempts
- Key inference time techniques that can be combined: repeated sampling (generating multiple attempts), fusion (synthesizing multiple responses), criticism and ranking of responses, verification of outputs.
- Verification falls into two categories of problems: automated (coding, formal math proofs) and manual(needs human judgment).
- Basic approaches like majority voting don't work well, we need better verifiers.
- Need deeper investigation into whether parallel or serial inference approaches are more effective
- As inference becomes a larger part of both training and deployment, high-throughput model serving infrastructure becomes increasingly critical.
- The line between inference and training is blurring, with inference results being fed back into training processes to improve model capabilities.
- Future models will need seamless self-improvement cycles that continuously enhance their capabilities.
- More similar to how humans learn through constant interaction and feedback rather than discrete training periods.
Publishing in the Generative AI Age
Hey Luke, why aren't you publishing new content? I am... but it's different in the age of generative AI. You don't see most of what I'm publishing these days and here's why.
The Ask Luke feature on this site uses the writings, videos, audio, and presentations I've published over the past 28 years to answer people's questions about digital product design. But since there's an endless amount of questions people could ask on this topic, I might not always have an answer. When this happens, the Ask Luke system basically tells people: "sorry I haven't written about this but here's some things I have written about." That's far from an ideal experience.
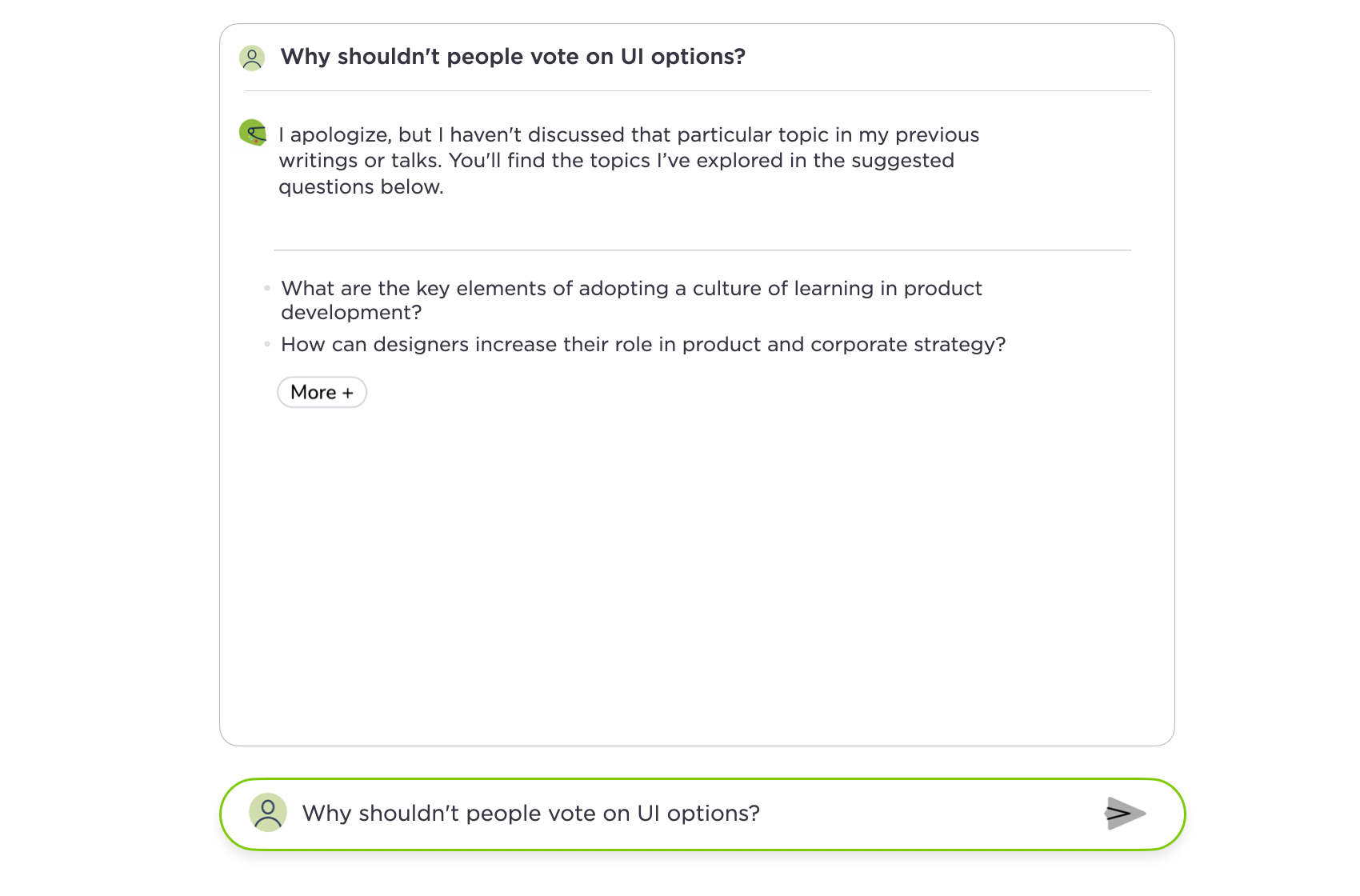{kind=link}
But just because I haven't taken the time to write an article or create a talk about a topic doesn't mean I don't have experiences or insights on it. Enter "saved questions". For any question Ask Luke wasn't able to answer, I can add information to answer it in the future in the form of a saved question. This admin feature allows the corpus of information Ask Luke uses to expand but it's invisible to people. Think of it as behind-the-scenes publishing.
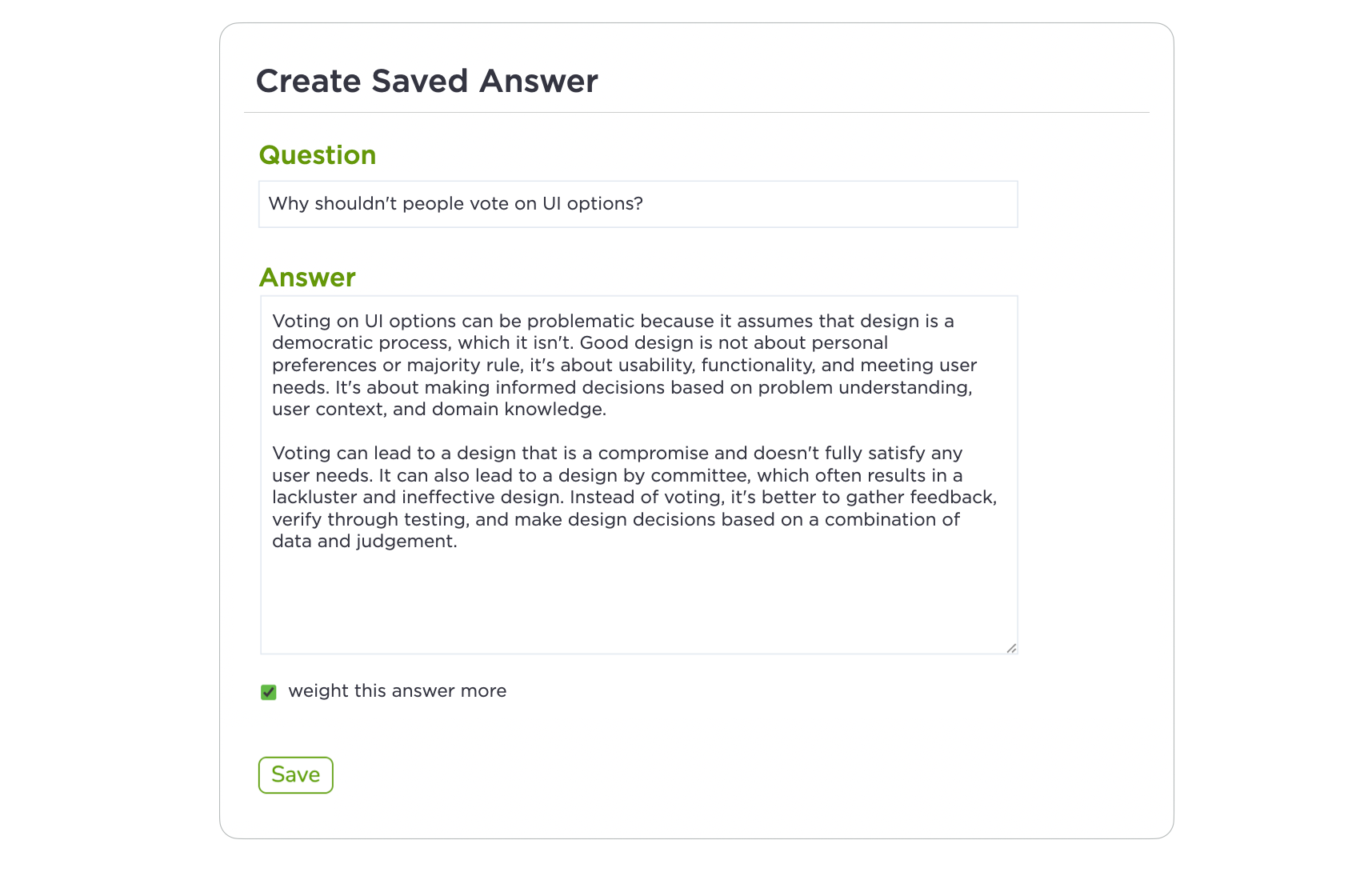{kind=link}
Since launching the Ask Luke feature in April 2023, I've added close to 500 saved questions to my content corpus. That's a lot of publishing that doesn't show up as blog posts or articles but can be used to generate answers when needed.
Each of these new bits of content can also be weighted more or less. With more weight, answers to similar questions will lean more on that specific answer.
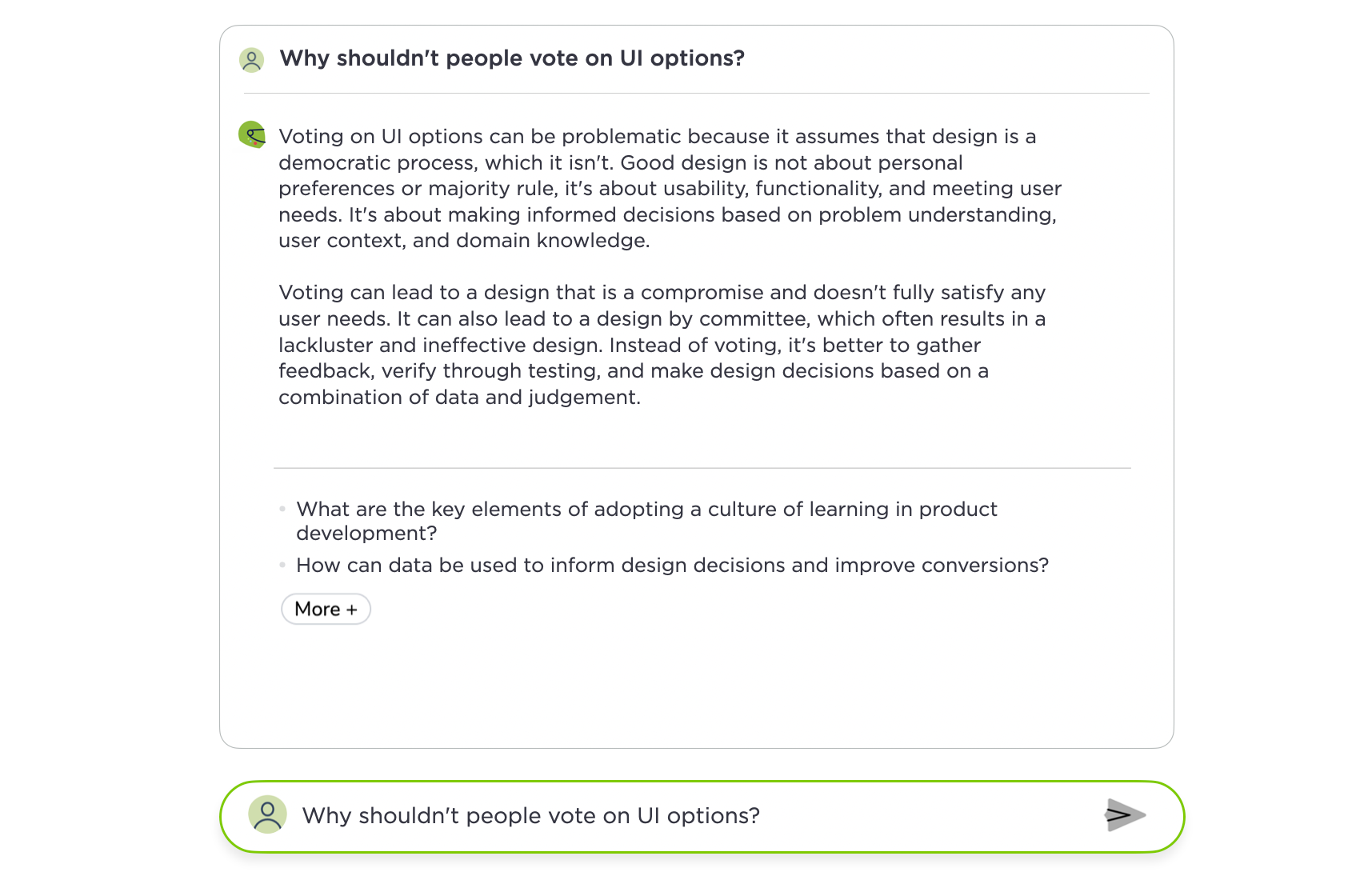{kind=link}
Without the extra weighting, saved questions are just another piece of content that can be used (or not) to answer similar questions. You can see the difference weighting makes by comparing these two replies to the same question. The first is weighted more heavily toward the saved question I added.
{kind=link}
Using this process triggered a bunch of thoughts. Should I publish these saved questions as new articles on my blog or keep them behind the scenes? What level of polish do these types of content additions need? On one hand, I can simply talk fluidly, record it, and let the AI figure what to use. Even if it's messy, the machines will use what they deem relevant, so why bother? On the other hand, I can write, edit, and polish the answers so the overall content corpus is quality is consistently high. Currently I lean more toward the later. But should I?
Zooming up a level, any content someone publishes is out of date the moment it goes live. But generated content, like Ask Luke answers, are only produced when a specific person has a specific question. So the overall content corpus is more like a fully malleable singular entity vs. a bunch of discrete articles or files. Different parts of this corpus can be used when needed, or not at all. That's a different way of thinking about publishing (overall corpus vs. individual artifacts) with more implications than I touched on here.